|
可能不少站长对于robots.txt协议这个概念,,还很陌生!现在很多类似dede,帝国等一些建站系统,在网站根目录,都会有默认的robots.txt协议文件。那么robots协议是什么,应该怎么写呢? 一、robots.txt协议是什么 robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它 " w: X4 }8 M; x5 P
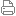
。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。百度官方建议,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。 如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。 以某seo站点为案例,其robots.txt协议文件如图所示: 二、robots.txt的写法及参数含义: 1.、User-agent:描述搜索引擎spider的名字。在“robots.txt“文件中,如果有多条
- g% ~4 z# i B" UUser-agent记录,说明有多个robot会受到该协议的约束。所以,“robots.txt”文件中至少要有一条User-
* }1 c% [. s: Z* t1 I7 H* ragent记录。如果该项的值设为*(通配符),则该协议对任何搜索引擎机器人均有效。在“robots.txt”文件 3 W! e: I4 y% i
中,“User-agent:*”这样的记录只能有一条。 2、Allow:/允许访问的路径 例如,Disallow:/home/后面有news、video、image等多个路径 接着使用Allow:/home/news,代表禁止访问/home/后的一切路径,但可以访问/home/news路径 2.、Disallow: / 禁止访问的路径 例如,Disallow: 5 O9 z, y( ^4 s% c# |7 A% L0 e% o
/home/news/data/,代表爬虫不能访问/home/news/data/后的所有URL,但能访问/home/news/data123 Disallow:
/ U Z) j* ] \# p/home/news/data,代表爬虫不能访问/home/news/data123、/home/news/datadasf等一系列以data开头的URL。 前者是精确屏蔽,后者是相对屏蔽 总结:上述是对“robots.txt协议是什么,robots.txt的写法!”相关的介绍!所以,Robots.txt文件是一个值得站长研究的协议,它合理的调配网站资源,有利于站点运营的快速发展。 6 H' n. F# q/ N4 K
那么关于robot.txt的介绍,强强seo就先说这些吧,希望能够帮助大家。 4 H& g% s2 Q- X
& p9 U2 C& Q- i4 {' u" U3 G
9 R h; s! v6 w# q6 ~& }
# Z" A2 `% i. @: s" Z( T: F |